
create table grades (
id serial primary key,
g int,
name text
);
insert into grades (g,
name )
select
random()*100,
substring(md5(random()::text ),0,floor(random()*31)::int)
from generate_series(0, 12141215);
CREATE INDEX g_idx ON grades (g);- id : row_id
- g : grade
- name : name
실습1
explain select * from grades;

- Seq Scan : 쿼리 계획 (Sequential Scan == Full Scan)
- 힙(heap) 영역으로 바로 가서 가져올 것이다. 순차적으로!
- cost -> 비용
- 첫 번째 숫자 0.00
- 첫 번째 페이지(Page)를 가져오는데 걸리는 시간 : 0.00(ms)가 걸림
- why? postgreSQL은 즉시 테이블로 이동하여 행을 가져오고, 결과를 얻었기 때문
- 첫 번째 결과를 얻는 데 거의 비용이 들지 않았음.
- 증가할 수 있다.
- postgreSQL은 데이터베이스에서 판단해서 가져오기 전에 어떤 작업을 수행하도록 결정할 수 있음.
- 예를 들어 집계 or 정렬과 같은 실제 가져오기 작업과는 무관하고 실제로 원하는 작업 전에 선행하는 작업이존재할 수 있다는 것을 뜻함.
- 두 번째 숫자 20083.01
- 쿼리를 실행하지 않았기 때문에 데이터베이스가 미리 예상하는 총 소요시간
- 실행 계획 이라고 생각하면 된다.
- 20초 안에 완료할 것으로 추정
- 첫 번째 숫자 0.00
- rows
- 정확한 숫자는 아니지만, 자체 통계에 기반한 대략적인 숫자를 빠르게 알려줌
- 가져올 행의 수(대략적인)
- 많은 좋아요 개수들을 읽어올 때 성능상 이점이 있음(쿼리가 날라가지 않기 때문에)
- 물론 정확하지 않기 때문에, 사용할 것인지 고려를 해봐야 함.
- width
- 행의 폭
- 한 행의 데이터를 표현하는 데 필요한 평균 바이트 수
실습2
explain select * from grades order by g;
- cost
- 0.43(ms)
- postgreSQL은 행을 가져오기 전에 어떤 작업(g를 기준으로 정렬)을 수행했다는 뜻
- 인덱스를 활용하여 정렬을 수행했기 때문에 그렇게 크게 걸리지는 않음
- 550초(실행 계획 or 수행)
- rows
- 대략 1200001개의 행
- width
- 원래는 40이 나와할 것 같았지만
- 23가 나온 이유는?
- heap에 접근해서 전체 열을 가져오는 부분을 제외했기 때문에
- 하나의 열 g만 접근하였기 때문에 줄어들었다.
- (틀릴 수도 있음)
실습3
explain select * from grades order by name;- 인덱스가 없는 name 열을 기준으로 오름차순 정렬 수행
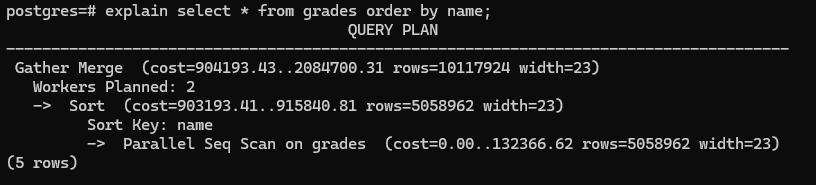
- Parallel Seq Scan on grades (cost=0.00..132366.62 rows=5058962 width=23)
- 병렬 순차 스캔
- cost : 0.00 -> 아직 정렬을 하지 않음
- 132초 걸림(row를 순회)
- rows -> 병렬로 처리하기 때문에 절반정도의 행을 읽은 것 같음(틀릴 수도 있음)
- width -> 전체 스캔해서 하나의 행 23Byte
- Sort Key: name
- 이름을 기준으로 정렬하겠다.
- Sort (cost=903193.41..915840.81 rows=5058962 width=23)
- cost
- 903193.41(ms)
- 903초(대략)
- cost
- Workers Planned: 2
- 병렬 작업을 수행
- 두 개의 스레드나 프로세스가 있었 때문에 결과를 Merge(병합)해야 함
- Gather Merge (cost=904193.43..2084700.31 rows=10117924 width=23)
- 그래서 결국 rows가 근사값(비슷하게) 10117924
- width = 23
- 23Byte
- 실제 결과를 얻기 위해 더 많은 작업을 해야함을 볼 수 있음
실습4
explain select id from grades;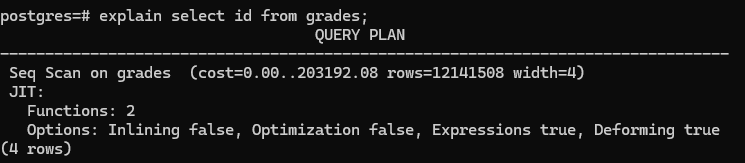
- cost=0.00
- 첫 번째 페이지를 가져오기 위해 테이블로 이동하는 비용은 0.00(ms)
- width=4
- 4Byte를 얻음
- id를 반환하게 하였고, id는 정수이며 4Byte이다
실습5
explain select name from grades;
- width = 15
- 이름(name)은 TEXT이기 때문
- 평균적으로 15Byte
실습6
explain select * from grades where id = 10;
- 인덱스를 스캔해서 힙으로 이동하여 몇 개의 행 값을 가져왔고, 이 과정은 0.43초가 걸렸으며
- 전체 작업을 수행(추정)하는 데 걸린 시간을 8.45밀리초
- 인덱스 스캔을 사용하였음(Index Scan)
- 힙으로 접근하였기 때문에 더 느림
explain select id from grades where id = 10;
- 힙으로 접근하지 않았기 때문에
- 전체 작업을 수행(추정)하는데 걸린 시간이 4.45밀리초 인 것을 확인 할 수 있음
- 실제로 이런 쿼리는 없지만
'DB관련 > 기타 DB' 카테고리의 다른 글
| 인덱싱 실습 (0) | 2024.03.20 |
|---|---|
| 백만 개의 행을 10초 만에 만들기 (postgre) (0) | 2024.03.17 |
| 테이블과 인덱스가 디스크에 저장되는 방법 (1) | 2024.03.16 |
create table grades (
id serial primary key,
g int,
name text
);
insert into grades (g,
name )
select
random()*100,
substring(md5(random()::text ),0,floor(random()*31)::int)
from generate_series(0, 12141215);
CREATE INDEX g_idx ON grades (g);- id : row_id
- g : grade
- name : name
실습1
explain select * from grades;
- Seq Scan : 쿼리 계획 (Sequential Scan == Full Scan)
- 힙(heap) 영역으로 바로 가서 가져올 것이다. 순차적으로!
- cost -> 비용
- 첫 번째 숫자 0.00
- 첫 번째 페이지(Page)를 가져오는데 걸리는 시간 : 0.00(ms)가 걸림
- why? postgreSQL은 즉시 테이블로 이동하여 행을 가져오고, 결과를 얻었기 때문
- 첫 번째 결과를 얻는 데 거의 비용이 들지 않았음.
- 증가할 수 있다.
- postgreSQL은 데이터베이스에서 판단해서 가져오기 전에 어떤 작업을 수행하도록 결정할 수 있음.
- 예를 들어 집계 or 정렬과 같은 실제 가져오기 작업과는 무관하고 실제로 원하는 작업 전에 선행하는 작업이존재할 수 있다는 것을 뜻함.
- 두 번째 숫자 20083.01
- 쿼리를 실행하지 않았기 때문에 데이터베이스가 미리 예상하는 총 소요시간
- 실행 계획 이라고 생각하면 된다.
- 20초 안에 완료할 것으로 추정
- 첫 번째 숫자 0.00
- rows
- 정확한 숫자는 아니지만, 자체 통계에 기반한 대략적인 숫자를 빠르게 알려줌
- 가져올 행의 수(대략적인)
- 많은 좋아요 개수들을 읽어올 때 성능상 이점이 있음(쿼리가 날라가지 않기 때문에)
- 물론 정확하지 않기 때문에, 사용할 것인지 고려를 해봐야 함.
- width
- 행의 폭
- 한 행의 데이터를 표현하는 데 필요한 평균 바이트 수
실습2
explain select * from grades order by g;- cost
- 0.43(ms)
- postgreSQL은 행을 가져오기 전에 어떤 작업(g를 기준으로 정렬)을 수행했다는 뜻
- 인덱스를 활용하여 정렬을 수행했기 때문에 그렇게 크게 걸리지는 않음
- 550초(실행 계획 or 수행)
- rows
- 대략 1200001개의 행
- width
- 원래는 40이 나와할 것 같았지만
- 23가 나온 이유는?
- heap에 접근해서 전체 열을 가져오는 부분을 제외했기 때문에
- 하나의 열 g만 접근하였기 때문에 줄어들었다.
- (틀릴 수도 있음)
실습3
explain select * from grades order by name;- 인덱스가 없는 name 열을 기준으로 오름차순 정렬 수행
- Parallel Seq Scan on grades (cost=0.00..132366.62 rows=5058962 width=23)
- 병렬 순차 스캔
- cost : 0.00 -> 아직 정렬을 하지 않음
- 132초 걸림(row를 순회)
- rows -> 병렬로 처리하기 때문에 절반정도의 행을 읽은 것 같음(틀릴 수도 있음)
- width -> 전체 스캔해서 하나의 행 23Byte
- Sort Key: name
- 이름을 기준으로 정렬하겠다.
- Sort (cost=903193.41..915840.81 rows=5058962 width=23)
- cost
- 903193.41(ms)
- 903초(대략)
- cost
- Workers Planned: 2
- 병렬 작업을 수행
- 두 개의 스레드나 프로세스가 있었 때문에 결과를 Merge(병합)해야 함
- Gather Merge (cost=904193.43..2084700.31 rows=10117924 width=23)
- 그래서 결국 rows가 근사값(비슷하게) 10117924
- width = 23
- 23Byte
- 실제 결과를 얻기 위해 더 많은 작업을 해야함을 볼 수 있음
실습4
explain select id from grades;- cost=0.00
- 첫 번째 페이지를 가져오기 위해 테이블로 이동하는 비용은 0.00(ms)
- width=4
- 4Byte를 얻음
- id를 반환하게 하였고, id는 정수이며 4Byte이다
실습5
explain select name from grades;- width = 15
- 이름(name)은 TEXT이기 때문
- 평균적으로 15Byte
실습6
explain select * from grades where id = 10;- 인덱스를 스캔해서 힙으로 이동하여 몇 개의 행 값을 가져왔고, 이 과정은 0.43초가 걸렸으며
- 전체 작업을 수행(추정)하는 데 걸린 시간을 8.45밀리초
- 인덱스 스캔을 사용하였음(Index Scan)
- 힙으로 접근하였기 때문에 더 느림
explain select id from grades where id = 10;- 힙으로 접근하지 않았기 때문에
- 전체 작업을 수행(추정)하는데 걸린 시간이 4.45밀리초 인 것을 확인 할 수 있음
- 실제로 이런 쿼리는 없지만
'DB관련 > 기타 DB' 카테고리의 다른 글
| 인덱싱 실습 (0) | 2024.03.20 |
|---|---|
| 백만 개의 행을 10초 만에 만들기 (postgre) (0) | 2024.03.17 |
| 테이블과 인덱스가 디스크에 저장되는 방법 (1) | 2024.03.16 |