
저장소 개념
- Table
- Row_id
- Page
- IO
- Heap data structure
- Index data structure b-tree
Table
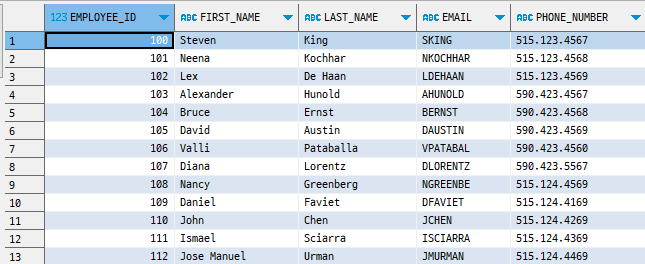
- EMPLOYEE_ID (Row_id)
- 특정 행을 고유하게 식별
- Postgres : 튜플 ID
Page
- Storage Model(row vs column store)에 따라 행은 논리적 페이지에 저장되고 읽혀진다.
- 데이터베이스는 단일 행을 읽는 것이 아니라, 단일 IO에서 한 페이지 이상을 읽으며, 해당 IO에서 많은 행을 얻는다.

- 우리 눈에는 두개의 행만 골라서 읽어온 것처럼 보이지만, 페이지 단위로 저장되어 있는 전체 영역을 스캔하며 필요한 행을 가지고 온 것.
- Page Size는 DB마다 다르다. (e.g. 8KB in postgres, 16KB in MySQL)
- Page에 3개의 행을 담고 있다고 가정하면, 1001행이 있을 때 대략 1001/3 = 333 ~ pages를 가질 수 있다.
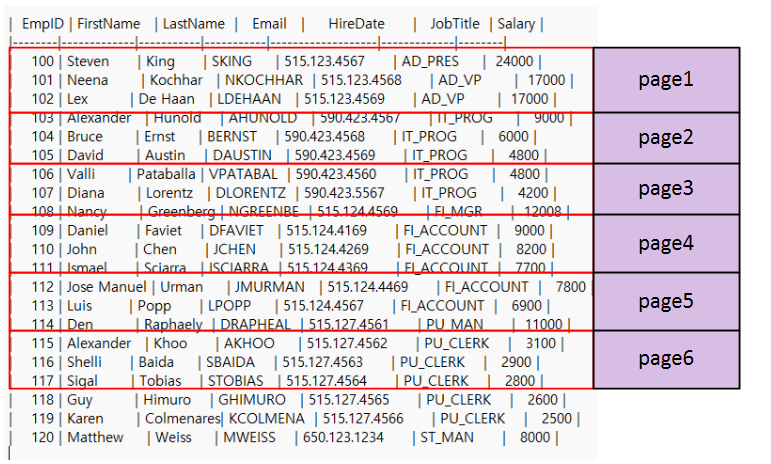
- 가정이고 저런 식으로 저장되지는 않는다. 그냥 나열된다는 느낌?
- 하나의 행을 불러오기 위해 각 page를 불러서 필요한 행을 찾는 작업 수행.
- page1에 없음 -> page2 -> page3 -> page4 이런 식으로 (index가 없다는 가정)
IO
- IO 작업(입력/출력)은 디스크에 대한 읽기 요청
- IO을 최소화 하기 위해 노력해야 함.(IO작업은 속도가 매우 느리기 때문)
- IO는 디스크 파티션 및 기타 요인에 따라 1page 이상을 가져올 수 있다.
- IO는 단일 행만을 읽을 수 없으며 , 복수의 행이 있는 page를 읽을 수 있다.
- IO를 줄여야 하는 이유로는 IO의 비용이 비싸기 때문
- 운영 체제의 일부 IO는 디스크가 아닌 운영 체제 캐시로 이동한다. (postgre)
- IO 작업이 디스크에 직접 기록되는 것이 아니라, 운영 체제의 캐시 메모리에 임시로 저장된다는 의미.
- 빠른 액세스와 성능 향상을 위해 사용
- 디스크에 대한 실제 기록은 나중에 수행될 수 있음
- 데이터를 캐시에 유지함으로써 디스크 I/O에 대한 대기 시간을 줄이고 시스템 전반적인 성능을 향상시킬 수 있음
HEAP
- 힙은 테이블의 모든 페이지가 다른 페이지에 이어서 저장되는 데이터 구조
- 테이블에 대한 모든 정보 및 실제 데이터가 저장되는 곳.
- 원하는 정보를 찾기 위해 수 많은 데이터를 읽어야 하므로 힙을 탐색하는 데는 많은 비용이 든다.
- 이런 이유로, 힙의 어느 부분을 읽어야 하는지 정확히 알려주는 인덱스(INDEX)가 필요
- 어떤 Page를 가져와야 하는지 알기 위해서(IO 작업을 줄이기 위해서)
INDEX
- 인덱스는 힙과 별도로 힙에 대한 "포인터"를 가진 또 다른 데이터 구조
- 데이터의 일부를 가지고 있으며 무언가를 빠르게 검색하는 데 사용
- 한 열 이상을 인덱싱할 수 있음
- 인덱스의 값을 찾으면, 힙으로 이동하며 모든 것이 있는 곳에서 더 많은 정보를 가지고 옴.
- 인덱스는 힙의 모든 페이지를 스캔하는 수고를 들이지 않고 힙에서 가져올 페이지를 정확하게 알려준다.
- 인덱스 역시 페이지로 저장되며, 인덱스의 항목을 가져오는 데 IO 비용이 발생
- 인덱스가 작을수록 메모리에 더 많이 들어갈 수 있으므로 검색 속도가 빨라짐
- 인덱스에 널리 사용되는 데이터 구조는 b-tree
느낌 점
- DB를 처음 배우고, 테이블 형태로 항상 데이터를 볼 수 있었기 때문에 실제로 디스크에도 순서대로 저장이 되는 줄!
- 하지만 그렇게 저장되지 않고 데이터는 페이지 단위로(논리적) 저장되어 있다는 점
- 인덱스를 설정해도, 너무 데이터가 커지다보면 인덱스에서 찾는 것이 더 느릴 수도 있다는 점.
- 인덱스를 통해 I/O를 줄여 성능을 향상시킬 수 있다는 점
'DB관련 > 기타 DB' 카테고리의 다른 글
| Explain으로 SQL Query Planner, Optimizer 이해하기 (0) | 2024.03.21 |
|---|---|
| 인덱싱 실습 (0) | 2024.03.20 |
| 백만 개의 행을 10초 만에 만들기 (postgre) (0) | 2024.03.17 |
저장소 개념
- Table
- Row_id
- Page
- IO
- Heap data structure
- Index data structure b-tree
Table
- EMPLOYEE_ID (Row_id)
- 특정 행을 고유하게 식별
- Postgres : 튜플 ID
Page
- Storage Model(row vs column store)에 따라 행은 논리적 페이지에 저장되고 읽혀진다.
- 데이터베이스는 단일 행을 읽는 것이 아니라, 단일 IO에서 한 페이지 이상을 읽으며, 해당 IO에서 많은 행을 얻는다.
- 우리 눈에는 두개의 행만 골라서 읽어온 것처럼 보이지만, 페이지 단위로 저장되어 있는 전체 영역을 스캔하며 필요한 행을 가지고 온 것.
- Page Size는 DB마다 다르다. (e.g. 8KB in postgres, 16KB in MySQL)
- Page에 3개의 행을 담고 있다고 가정하면, 1001행이 있을 때 대략 1001/3 = 333 ~ pages를 가질 수 있다.
- 가정이고 저런 식으로 저장되지는 않는다. 그냥 나열된다는 느낌?
- 하나의 행을 불러오기 위해 각 page를 불러서 필요한 행을 찾는 작업 수행.
- page1에 없음 -> page2 -> page3 -> page4 이런 식으로 (index가 없다는 가정)
IO
- IO 작업(입력/출력)은 디스크에 대한 읽기 요청
- IO을 최소화 하기 위해 노력해야 함.(IO작업은 속도가 매우 느리기 때문)
- IO는 디스크 파티션 및 기타 요인에 따라 1page 이상을 가져올 수 있다.
- IO는 단일 행만을 읽을 수 없으며 , 복수의 행이 있는 page를 읽을 수 있다.
- IO를 줄여야 하는 이유로는 IO의 비용이 비싸기 때문
- 운영 체제의 일부 IO는 디스크가 아닌 운영 체제 캐시로 이동한다. (postgre)
- IO 작업이 디스크에 직접 기록되는 것이 아니라, 운영 체제의 캐시 메모리에 임시로 저장된다는 의미.
- 빠른 액세스와 성능 향상을 위해 사용
- 디스크에 대한 실제 기록은 나중에 수행될 수 있음
- 데이터를 캐시에 유지함으로써 디스크 I/O에 대한 대기 시간을 줄이고 시스템 전반적인 성능을 향상시킬 수 있음
HEAP
- 힙은 테이블의 모든 페이지가 다른 페이지에 이어서 저장되는 데이터 구조
- 테이블에 대한 모든 정보 및 실제 데이터가 저장되는 곳.
- 원하는 정보를 찾기 위해 수 많은 데이터를 읽어야 하므로 힙을 탐색하는 데는 많은 비용이 든다.
- 이런 이유로, 힙의 어느 부분을 읽어야 하는지 정확히 알려주는 인덱스(INDEX)가 필요
- 어떤 Page를 가져와야 하는지 알기 위해서(IO 작업을 줄이기 위해서)
INDEX
- 인덱스는 힙과 별도로 힙에 대한 "포인터"를 가진 또 다른 데이터 구조
- 데이터의 일부를 가지고 있으며 무언가를 빠르게 검색하는 데 사용
- 한 열 이상을 인덱싱할 수 있음
- 인덱스의 값을 찾으면, 힙으로 이동하며 모든 것이 있는 곳에서 더 많은 정보를 가지고 옴.
- 인덱스는 힙의 모든 페이지를 스캔하는 수고를 들이지 않고 힙에서 가져올 페이지를 정확하게 알려준다.
- 인덱스 역시 페이지로 저장되며, 인덱스의 항목을 가져오는 데 IO 비용이 발생
- 인덱스가 작을수록 메모리에 더 많이 들어갈 수 있으므로 검색 속도가 빨라짐
- 인덱스에 널리 사용되는 데이터 구조는 b-tree
느낌 점
- DB를 처음 배우고, 테이블 형태로 항상 데이터를 볼 수 있었기 때문에 실제로 디스크에도 순서대로 저장이 되는 줄!
- 하지만 그렇게 저장되지 않고 데이터는 페이지 단위로(논리적) 저장되어 있다는 점
- 인덱스를 설정해도, 너무 데이터가 커지다보면 인덱스에서 찾는 것이 더 느릴 수도 있다는 점.
- 인덱스를 통해 I/O를 줄여 성능을 향상시킬 수 있다는 점
'DB관련 > 기타 DB' 카테고리의 다른 글
| Explain으로 SQL Query Planner, Optimizer 이해하기 (0) | 2024.03.21 |
|---|---|
| 인덱싱 실습 (0) | 2024.03.20 |
| 백만 개의 행을 10초 만에 만들기 (postgre) (0) | 2024.03.17 |